
HMI как интеллектуальные периферийные устройства
Программное обеспечение HMI можно использовать для создания ценности из быстро увеличивающегося объема промышленных данных. По сведениям корпорации International Data Corp. (IDC), в 2025 г. каждый день будет создаваться 463 Эбайт (1 Эбайт равен 1 квинтиллиону байт) данных [1]. При этом большая часть этих данных будет передана следующими устройствами и технологиями:
- интеллектуальными датчиками и другими устройствами промышленного «Интернета вещей» (Industrial Internet of Things, IIoT);
- программируемыми логическими контроллерами (ПЛК);
- другими специализированными контроллерами, например контроллерами автоматизации;
- системами сбора промышленных данных.
Устройства всех перечисленных выше типов продолжают добавлять в свою структуру датчики, а большее число используемых датчиков, естественно, ведет и к большему объему собранных данных. Экспоненциальный рост только одних промышленных систем уже опережает доступную пропускную способность сети. Большая часть данных от машин и процессов остается неиспользованной, но получение доступа к этим сведениям имеет решающее значение для получения ценной бизнес-информации, буквально ее кладезем.
Эффективно использовать данные помогает их обработка с помощью программного обеспечения HMI, развернутого рядом с источником таких данных. Для этого роль HMI должна эволюционировать
Новые роли для программного обеспечения HMI
Программное обеспечение HMI, установленное на периферийных устройствах, должно соответствовать постоянно растущим требованиям к тому, как все типы данных должны быть получены, отсортированы, проанализированы и уточнены. Огромный объем собираемых данных означает, что важную роль в общем плане цифровой трансформации для более разумных операций на операционном уровне должны играть передовая аналитика и машинное обучение.
HMI, как правило, работают с такими источниками данных, как ПЛК и датчики. Традиционно HMI использовались в качестве инструмента визуализации, а иногда и в качестве сборщика данных, просматриваемых на специальной панели управления, мобильном устройстве или в веб-браузере. Современные HMI по-прежнему должны выполнять эти роли, но также собирать данные в реальном времени, хранить их локально для дальнейшего анализа и использовать для поиска закономерностей и выводов, необходимых для составления прогнозов (рис. 1).
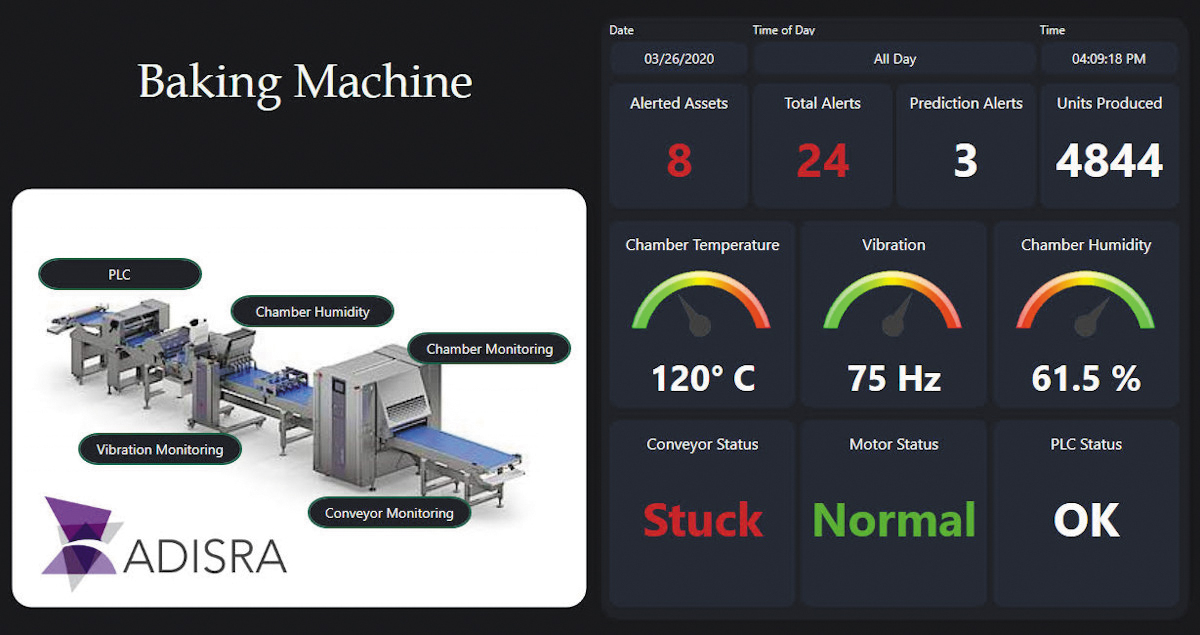
Рис. 1. Традиционные HMI технологического и производственного оборудования использовались только для визуализации, но новые продукты, такие как SmartView от компании ADISRA, поддерживают хранение и анализ данных непосредственно на периферии.
Все изображения предоставлено компанией ADISRA
Сейчас HMI развиваются как источник данных для обеспечения машинного обучения в реальном времени. Соответственно, для обучения моделей данные процесса временного ряда должны коррелировать с данными о нарушениях процесса и сопровождающих их событиях. Это позволяет таким моделям определять качество продукта в ходе производства или прогнозировать состояние критически важного оборудования. Модели машинного обучения работают лучше всего, когда для них доступны большие объемы данных с высокой точностью. Прогнозное техническое обслуживание возможно только тогда, когда эти модели заранее обнаруживают отклонения от обычного поведения и указывают на возможный надвигающийся отказ, способный привести к простою оборудования производственной линии или машины.
Четыре способа проверить качество промышленных данных
Чтобы перейти от необработанных данных к аналитическим, человеко-машинный интерфейс должен анализировать входящие сведения от физических активов предприятия и промышленных элементов управления и хранить их в организованном порядке. Решающую роль в закладке основы, необходимой для прогнозного моделирования, играет объединение исторических данных с данными, поступающими в реальном времени.
Модели машинного обучения разрабатываются путем изучения достаточного количества данных, представляющих довольно разнообразный набор, чтобы охватить как можно больше примеров успеха и неудач в соотношении, например, 70/30 (успех/неудача).
Для того чтобы подобрать правильный набор данных с проверенным качеством, требуется время. Также их нужно очистить следующим образом:
- удалить значения с нулевым значением — NULL value (значение NULL в реляционной базе данных используется, если значение в столбце неизвестно или отсутствует);
- убедиться в том, что данные верны для желаемого сигнала и масштабирования;
- обеспечить достаточную частоту дискретизации;
- подобрать интересующие условия.
При выполнении анализа числовых данных (они необходимы для выявления тенденций) поисковыми методами может быть выброшен большой объем исторических данных, но часто требуется получать и новые текущие данные. При этом пользователи должны убедиться, что обучающий набор не имеет встроенной систематической ошибки. Только после подтверждения достоверности данных можно создавать и применять модели машинного обучения.
Как правильно построить модель машинного обучения
Данные, собранные в реальном времени, поддерживают построение и уточнение модели машинного обучения. Сейчас ведутся споры о том, должно ли после создания модели машинного обучения каждое пограничное устройство иметь возможность изменять модель машинного обучения или такие обновления должны контролировать исключительно люди.
Преимущество возможности изменять модель каждому периферийному устройству состоит в том, что они могут адаптироваться. Однако следствием динамического изменения модели является то, что модели машинного обучения для каждого граничного устройства могут различаться. Последовательно обновляемые модели с большей вероятностью сведут к минимуму проблемы с их поддержкой.
Большинство пользователей начинают процесс разработки модели с контролируемого обучения таким алгоритмам, как линейная регрессия, логистическая регрессия и нейронные сети. Большая часть сегодняшней практической ценности модели — это обучение под контролем человека или как минимум под его наблюдением. Затем уже можно приступить к применению методов глубокого обучения на основе одних лишь данных.
Когда модель машинного обучения находится в приемлемом с точки зрения ее «разумности» состоянии, ее можно развернуть на граничном устройстве, где она сможет работать с данными в реальном времени и искать аномалии. При обнаружении каких-либо аномалий HMI может уведомить пользователя, отправив сигнал тревоги.
Архитектура современного HMI, пограничная аналитика
Роль современного HMI заключается не только в сборе данных, но и в идентификации элементов, событий или наблюдений, не соответствующих ожидаемому шаблону. У такого HMI есть хорошие возможности не только для того, чтобы делать выводы на основе данных и обнаруживать те или иные аномалии, но и для отправки аварийных сигналов через экран, в виде текстовых сообщений или отправления электронных писем оператору о фактических или потенциальных проблемах.
Выполняя обнаружение ближе к источнику данных, человеко-машинный интерфейс позволяет реализовать более раннее оповещение без задержки, свойственной отправке данных в облако. HMI может находить известные шаблоны, способные привести к обнаружению отказа на критически важном элементе оборудования, при этом и логический вывод, и действия на этом уровне обрабатываются локально (рис. 2).

Рис. 2. Расположенные на периферии HMI хорошо подходят для выполнения аналитики и быстрой доставки сообщений и сигналов тревоги пользователям
HMI также могут выполнять и предварительную обработку данных. Благодаря расположению HMI на периферии, его возможности по созданию и генерации выводов в реальном времени он может классифицировать, обнаруживать и сегментировать данные перед их отправкой в облако. Это обеспечивает эффективность восходящей обработки и упрощает организацию сети.
Однако концепция, в рамках которой пограничное устройство должно передавать необработанные, агрегированные или прогнозные данные в облако для дальнейшей аналитики, несколько спорна. Для оптимизации моделей машинного обучения в высокоуровневых или облачных системах потребуются необработанные данные максимальной точности. К сожалению, это может создать для пользователя техническую (аппаратную и сетевую) нагрузку и привести к финансовым затратам.
Необходимость в фильтрации промышленных данных
Основываясь на оценке корпорации IDC, что к 2025 г. ежедневно будет создаваться 463 Эбайт данных, о чем было сказано в начале статьи, пользователи должны принимать осторожные решения о передаче данных, исходя из объема хранилища и пропускной способности сети, необходимой для обновления данных в том месте, где они необходимы для анализа (рис. 3).

Рис. 3. HMI SmartView от компании ADISRA выходит за рамки простой визуализации и помогает OEM-производителям и конечным пользователям управлять передачей данных и выполнять аналитику машинного обучения
Подход на основе необработанных данных предоставляет лучшие базовые данные для моделей машинного обучения. Однако из-за того, что создается огромный объем информации, в этом случае может быть физически сложно передать данные в реальном времени. Когда агрегированные или прогнозные данные в реальном времени предварительно обрабатываются на границе и передаются, объем для передачи ниже. Впрочем, пользователи должны знать, что этот подход может фильтровать или скрывать информацию, позволяя предвзятости проникать в модель машинного обучения.
Другой вариант — отправка агрегированных или прогнозных данных в реальном времени и настройка другого канала для отправки необработанных данных с меньшей скоростью. Потенциальным недостатком является то, что при таком подходе очередь связи может быть быстро заполнена.
Экономические затраты на приобретение пропускной способности сети и устройств хранения должны быть сбалансированы с доступными техническими практическими задачами, такими как определение достаточной стабильности сети. Эти факторы будут влиять на то, где можно развернуть машинное обучение: на границе, в облаке или в обеих точках сразу. Здесь необходим поход на основе функционально-стоимостного анализа.
Расширенная аналитика в HMI и обнаружение аномалий
С помощью современных HMI возможна расширенная аналитика. Большая часть мировых данных —- это потоковые данные и данные временных рядов, аномалии которых предоставляют важную информацию, указывающую на критические ситуации. Существует множество вариантов использования HMI для обнаружения аномалий, включая основу профилактического и прогнозного технического обслуживания, обнаружения неисправностей и мониторинга текущего состояния технологического и производственного оборудования, а также отдельных критически важных машин и механизмов.
Аномалии определяются как момент времени, когда поведение системы становится необычным и сильно отличается от ее поведения в прошлом. Аномалии могут быть пространственными (значение выходит за пределы типичного диапазона) или временными (значение не выходит за пределы типичного диапазона), но последовательность, в которой они возникают, необычна. Метки состояний могут быть связаны с аномалиями и классифицировать их как временные или пространственные. Система аварийной сигнализации также может назначать взвешенные значения для прогнозирования отказа на основе приоритета, важности и частоты.
Любой современный HMI также должен изначально поддерживать механизмы для отправки и получения сообщений с отслеживанием состояния и гарантировать актуальность и достоверность данных удаленного устройства. Связь с отслеживанием состояния может быть обеспечена с помощью таких протоколов, как MQTT (Message Queue Telemetry Transport — легкий сетевой протокол, работающий поверх TCP/IP) и Kafka (распределенный программный брокер сообщений, проект с открытым исходным кодом), а управление состоянием — спецификацией Sparkplug B.
Данные, попавшие в облако, можно агрегировать и объединить с данными из нескольких источников. Ценность здесь заключается в том, что пользователи могут рассматривать несколько операций или весь парк оборудования вместе, независимо от их физического местоположения. Облачную фильтрацию и аналитические модели можно использовать для уточнения данных в рамках глубокого анализа с целью прогнозирования поведения и тенденций, таких как среднее время наработки на отказ (MTBF) или окончание срока службы машин. Затем эту информацию можно развернуть обратно в модели машинного обучения, расположенные на периферии и работающие в HMI, чтобы улучшить работу этих моделей.
Пять требований к современным HMI
Если прогноз корпорации IDC хоть сколько-нибудь близок к правильному, то роль HMI будет возрастать и необходимо соответствующим образом их развить, чтобы вместить огромные объемы данных. Современные HMI могут подключаться к большому количеству машинных данных, чтобы:
- отслеживать и анализировать объемы данных в режиме реального времени;
- визуализировать их в последовательной и удобной для пользователя форме;
- помогать пользователям принимать разумные решения;
- хранить данные удобным способом так, чтобы их можно было добывать по желанию пользователя;
- преодолевать компромиссы и ограничения.
Это новая роль HMI, поскольку развертывается все больше датчиков, а зависимость от машин продолжает расти. Критический характер и функции этих машин будут расширяться, и человеко-машинный интерфейс станет мозгом интеллектуальной периферии.
 26 марта, 2024
26 марта, 2024 5 сентября, 2018
5 сентября, 2018 6 марта, 2018
6 марта, 2018